" height="2.0768733066194303px" id="D9zvikPGQ" transform="translate(2.998 0.199)" width="5.731236321640176px"/><path d="M 0.187 0.574 L 3.457 3.297 C 3.457 3.297 3.662 3.483 3.885 3.483 C 4.089 3.483 4.312 3.297 4.312 3.297 L 7.582 0.574 C 7.713 0.481 7.768 0.313 7.675 0.163 C 7.601 0.014 7.415 -0.042 7.267 0.033 L 4.182 2.103 L 3.903 2.271 C 3.885 2.271 3.847 2.271 3.81 2.271 L 3.531 2.103 L 0.447 0.033 C 0.298 -0.042 0.131 0.033 0.038 0.163 C -0.036 0.313 0.001 0.481 0.131 0.574 Z" fill="rgb(0, 0, 0)" height="3.483465559558452px" id="XHPDa9C06" transform="translate(1.975 1.124)" width="7.7215397232611345px"/><path d="M 1.933 5.727 C 2.063 5.652 2.1 5.503 2.044 5.372 L 0.966 2.91 C 0.966 2.892 0.966 2.873 0.966 2.854 L 2.044 0.392 C 2.1 0.262 2.044 0.113 1.933 0.038 C 1.803 -0.037 1.654 0.001 1.58 0.131 L 0.112 2.519 C 0.112 2.519 0 2.705 0 2.873 C 0 3.078 0.112 3.246 0.112 3.246 L 1.58 5.634 C 1.654 5.745 1.803 5.783 1.933 5.727 Z" fill="rgb(0, 0, 0)" height="5.752520201428617px" id="fSIVTyYyB" transform="translate(9.688 3.208)" width="2.0692037208998664px"/><path d="M 2.899 0.187 L 0.186 3.47 C 0.186 3.47 0 3.675 0 3.899 C 0 4.104 0.186 4.328 0.186 4.328 L 2.899 7.611 C 2.992 7.741 3.159 7.797 3.308 7.704 C 3.456 7.629 3.512 7.443 3.438 7.294 L 1.375 4.197 L 1.208 3.918 C 1.208 3.899 1.208 3.862 1.208 3.824 L 1.375 3.545 L 3.438 0.448 C 3.512 0.299 3.438 0.131 3.308 0.038 C 3.159 -0.037 2.992 0.001 2.899 0.131 Z" fill="rgb(0, 0, 0)" height="7.750209501286653px" id="XEy5_M_wF" transform="translate(7.365 2.182)" width="3.470578512630766px"/><path d="M 0.026 1.94 C 0.1 2.07 0.249 2.108 0.379 2.052 L 2.832 0.97 C 2.85 0.97 2.869 0.97 2.887 0.97 L 5.34 2.052 C 5.47 2.108 5.619 2.052 5.693 1.94 C 5.768 1.809 5.731 1.66 5.6 1.585 L 3.222 0.112 C 3.222 0.112 3.036 0 2.869 0 C 2.664 0 2.497 0.112 2.497 0.112 L 0.119 1.585 C 0.007 1.66 -0.03 1.809 0.026 1.94 Z" fill="rgb(0, 0, 0)" height="2.0768899917602535px" id="GVAyPotmc" transform="translate(3.029 9.923)" width="5.731234655014601px"/><path d="M 7.535 2.91 L 4.264 0.187 C 4.264 0.187 4.06 0 3.837 0 C 3.633 0 3.41 0.187 3.41 0.187 L 0.139 2.91 C 0.009 3.003 -0.047 3.171 0.046 3.32 C 0.12 3.469 0.306 3.525 0.455 3.451 L 3.54 1.38 L 3.818 1.212 C 3.837 1.212 3.874 1.212 3.911 1.212 L 4.19 1.38 L 7.275 3.451 C 7.423 3.525 7.591 3.451 7.684 3.32 C 7.758 3.171 7.721 3.003 7.591 2.91 Z" fill="rgb(0, 0, 0)" height="3.483478327665332px" id="UJGiliWlr" transform="translate(2.06 7.592)" width="7.721540951544936px"/><path d="M 0.137 0.026 C 0.007 0.1 -0.031 0.25 0.025 0.38 L 1.103 2.842 C 1.103 2.861 1.103 2.879 1.103 2.898 L 0.025 5.36 C -0.031 5.491 0.025 5.64 0.137 5.715 C 0.267 5.789 0.415 5.752 0.49 5.621 L 1.958 3.234 C 1.958 3.234 2.069 3.047 2.069 2.879 C 2.069 2.674 1.958 2.506 1.958 2.506 L 0.49 0.119 C 0.415 0.007 0.267 -0.03 0.137 0.026 Z" fill="rgb(0, 0, 0)" height="5.752526692867306px" id="DM37PXgJd" transform="translate(0 3.239)" width="2.0691900389284807px"/><path d="M 0.572 7.6 L 3.285 4.318 C 3.285 4.318 3.471 4.112 3.471 3.889 C 3.471 3.683 3.285 3.46 3.285 3.46 L 0.572 0.14 C 0.479 0.009 0.312 -0.047 0.163 0.046 C 0.014 0.121 -0.042 0.307 0.033 0.457 L 2.095 3.553 L 2.263 3.833 C 2.263 3.851 2.263 3.889 2.263 3.926 L 2.095 4.206 L 0.033 7.302 C -0.042 7.451 0.033 7.619 0.163 7.712 C 0.312 7.787 0.479 7.749 0.572 7.619 Z" fill="rgb(0, 0, 0)" height="7.750215230634018px" id="omz1nxiI6" transform="translate(0.922 2.23)" width="3.470588058544221px"/><path d="M 4.007 1.424 C 4.508 1.424 4.897 1.536 5.231 1.759 C 5.565 1.983 5.787 2.29 5.927 2.709 L 7.735 2.709 C 7.513 1.843 7.067 1.173 6.427 0.698 C 5.787 0.223 4.981 0 3.979 0 C 2.977 0 2.504 0.168 1.92 0.531 C 1.308 0.866 0.863 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.501 6.423 C 0.835 7.066 1.308 7.568 1.92 7.903 C 2.532 8.267 3.2 8.434 3.979 8.434 C 4.758 8.434 5.76 8.183 6.4 7.708 C 7.04 7.205 7.485 6.563 7.735 5.725 L 5.927 5.725 C 5.62 6.591 4.981 7.01 3.979 7.01 C 2.977 7.01 2.755 6.758 2.337 6.256 C 1.92 5.753 1.725 5.083 1.725 4.189 C 1.725 3.295 1.92 2.625 2.337 2.15 C 2.755 1.648 3.283 1.424 3.979 1.424 Z" fill="rgb(0, 0, 0)" height="8.434076339054002px" id="fGIMtJKmR" transform="translate(15.609 3.128)" width="7.735096310284753px"/><path d="M 6.093 0.503 C 5.481 0.168 4.814 0 4.034 0 C 3.255 0 2.532 0.168 1.92 0.531 C 1.308 0.866 0.835 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.529 6.423 C 0.89 7.066 1.363 7.568 1.976 7.903 C 2.588 8.267 3.283 8.434 4.062 8.434 C 4.841 8.434 5.815 8.183 6.455 7.708 C 7.095 7.233 7.54 6.619 7.791 5.865 L 5.982 5.865 C 5.62 6.619 4.98 7.01 4.062 7.01 C 3.144 7.01 2.894 6.814 2.476 6.423 C 2.031 6.032 1.809 5.502 1.753 4.859 L 7.958 4.859 C 7.985 4.608 8.013 4.329 8.013 4.022 C 8.013 3.24 7.846 2.541 7.512 1.927 C 7.179 1.313 6.706 0.838 6.121 0.503 Z M 1.725 3.491 C 1.809 2.849 2.059 2.346 2.476 1.983 C 2.894 1.62 3.395 1.424 3.979 1.424 C 4.563 1.424 5.147 1.62 5.593 1.983 C 6.038 2.346 6.26 2.849 6.26 3.491 L 1.753 3.491 Z" fill="rgb(0, 0, 0)" height="8.434076339054002px" id="qaL5FVZij" transform="translate(24.013 3.128)" width="8.01332295195354px"/><path d="M 5.815 0.391 C 5.314 0.112 4.73 0 4.09 0 C 3.45 0 3.144 0.084 2.727 0.279 C 2.309 0.475 1.948 0.726 1.669 1.061 L 1.669 0.14 L 0 0.14 L 0 8.294 L 1.669 8.294 L 1.669 3.742 C 1.669 3.016 1.864 2.458 2.226 2.067 C 2.587 1.676 3.088 1.48 3.729 1.48 C 4.368 1.48 4.841 1.676 5.231 2.067 C 5.592 2.458 5.787 3.016 5.787 3.742 L 5.787 8.294 L 7.457 8.294 L 7.457 3.491 C 7.457 2.737 7.318 2.122 7.04 1.592 C 6.761 1.061 6.344 0.67 5.843 0.419 Z" fill="rgb(0, 0, 0)" height="8.294435702953454px" id="WDjXqIjZT" transform="translate(33.166 3.128)" width="7.4567073744807075px"/><path d="M 2.643 0 L 0.946 0 L 0.946 2.039 L 0 2.039 L 0 3.407 L 0.946 3.407 L 0.946 7.931 C 0.946 8.741 1.141 9.3 1.558 9.663 C 1.948 10.026 2.532 10.193 3.311 10.193 L 4.647 10.193 L 4.647 8.797 L 3.617 8.797 C 3.283 8.797 3.033 8.741 2.894 8.602 C 2.755 8.462 2.671 8.239 2.671 7.931 L 2.671 3.407 L 4.647 3.407 L 4.647 2.039 L 2.671 2.039 L 2.671 0 Z" fill="rgb(0, 0, 0)" height="10.193494685087567px" id="nZ8KAi6H2" transform="translate(41.458 1.229)" width="4.646524285330045px"/><path d="M 1.085 0 C 0.779 0 0.528 0.112 0.306 0.307 C 0.111 0.503 0 0.782 0 1.089 C 0 1.396 0.111 1.648 0.306 1.871 C 0.501 2.095 0.779 2.178 1.085 2.178 C 1.391 2.178 1.642 2.067 1.836 1.871 C 2.031 1.676 2.142 1.396 2.142 1.089 C 2.142 0.782 2.031 0.531 1.836 0.307 C 1.642 0.112 1.391 0 1.085 0 Z" fill="rgb(0, 0, 0)" height="2.1783368721996954px" id="xofK7bnqV" transform="translate(47.384 0)" width="2.1424521645366994px"/><path d="M 1.669 0 L 0 0 L 0 8.155 L 1.669 8.155 Z" fill="rgb(0, 0, 0)" height="8.154788300335934px" id="owXtEW3wx" transform="translate(47.607 3.267)" width="1.6694896185170123px"/><path d="M 1.085 0 C 0.779 0 0.529 0.112 0.306 0.307 C 0.111 0.503 0 0.782 0 1.089 C 0 1.396 0.111 1.648 0.306 1.871 C 0.501 2.067 0.779 2.178 1.085 2.178 C 1.391 2.178 1.642 2.067 1.836 1.871 C 2.031 1.676 2.142 1.396 2.142 1.089 C 2.142 0.782 2.031 0.531 1.836 0.307 C 1.642 0.112 1.391 0 1.085 0 Z" fill="rgb(0, 0, 0)" height="2.1783368721996954px" id="qYXTLcef6" transform="translate(55.842 0)" width="2.1424521645367136px"/><path d="M 4.007 7.01 C 3.311 7.01 2.783 6.758 2.365 6.256 C 1.948 5.753 1.753 5.083 1.753 4.189 C 1.753 3.295 1.948 2.625 2.365 2.15 C 2.783 1.648 3.311 1.424 4.007 1.424 C 4.702 1.424 4.897 1.536 5.231 1.759 C 5.565 1.983 5.788 2.29 5.926 2.709 L 7.735 2.709 C 7.513 1.843 7.067 1.173 6.427 0.698 C 5.788 0.223 4.981 0 3.979 0 C 2.977 0 2.504 0.168 1.92 0.531 C 1.308 0.866 0.862 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.501 6.423 C 0.835 7.066 1.308 7.568 1.92 7.903 C 2.532 8.267 3.2 8.434 3.979 8.434 C 4.758 8.434 5.76 8.183 6.4 7.708 C 7.04 7.205 7.485 6.563 7.735 5.725 L 5.926 5.725 C 5.621 6.591 4.981 7.01 3.979 7.01 Z" fill="rgb(0, 0, 0)" height="8.434076339054002px" id="YVPoMPmqZ" transform="translate(59.265 3.128)" width="7.735226155870485px"/><path d="M 6.872 3.268 L 2.643 3.268 L 2.643 2.681 C 2.643 2.206 2.754 1.871 2.949 1.676 C 3.144 1.508 3.478 1.396 3.923 1.396 L 3.923 0 C 2.921 0 2.17 0.223 1.697 0.642 C 1.196 1.061 0.946 1.759 0.946 2.681 L 0.946 3.268 L 0 3.268 L 0 4.636 L 0.946 4.636 L 0.946 11.422 L 2.643 11.422 L 2.643 4.636 L 5.203 4.636 L 5.203 11.422 L 6.872 11.422 Z" fill="rgb(0, 0, 0)" height="11.422308710362525px" id="mR0Sii5R7" transform="translate(50.863 0)" width="6.872402238697973px"/></g></svg>)
" width="11.757210121961878px"><path d="M 5.706 0.137 C 5.631 0.007 5.483 -0.031 5.353 0.025 L 2.9 1.107 C 2.881 1.107 2.862 1.107 2.844 1.107 L 0.391 0.025 C 0.261 -0.031 0.112 0.025 0.038 0.137 C -0.036 0.268 0.001 0.417 0.131 0.491 L 2.509 1.965 C 2.509 1.965 2.695 2.077 2.862 2.077 C 3.067 2.077 3.234 1.965 3.234 1.965 L 5.613 0.491 C 5.724 0.417 5.761 0.268 5.706 0.137 Z" fill="rgb(255, 255, 255)" height="2.0768733060957265px" id="JOqgQgeXH" transform="translate(2.998 0)" width="5.731236321640178px"/><path d="M 0.187 0.574 L 3.457 3.297 C 3.457 3.297 3.662 3.483 3.885 3.483 C 4.089 3.483 4.312 3.297 4.312 3.297 L 7.582 0.574 C 7.713 0.481 7.768 0.313 7.675 0.163 C 7.601 0.014 7.415 -0.042 7.267 0.033 L 4.182 2.103 L 3.903 2.271 C 3.885 2.271 3.847 2.271 3.81 2.271 L 3.531 2.103 L 0.447 0.033 C 0.298 -0.042 0.131 0.033 0.038 0.163 C -0.036 0.313 0.001 0.481 0.131 0.574 Z" fill="rgb(255, 255, 255)" height="3.483465570588767px" id="Zd5XdemVt" transform="translate(1.975 0.925)" width="7.721539723261137px"/><path d="M 1.933 5.727 C 2.063 5.652 2.1 5.503 2.044 5.372 L 0.966 2.91 C 0.966 2.892 0.966 2.873 0.966 2.854 L 2.044 0.392 C 2.1 0.262 2.044 0.113 1.933 0.038 C 1.803 -0.037 1.654 0.001 1.58 0.131 L 0.112 2.519 C 0.112 2.519 0 2.705 0 2.873 C 0 3.078 0.112 3.246 0.112 3.246 L 1.58 5.634 C 1.654 5.745 1.803 5.783 1.933 5.727 Z" fill="rgb(255, 255, 255)" height="5.752520201428616px" id="wm4QOyIBO" transform="translate(9.688 3.009)" width="2.069203720899866px"/><path d="M 2.899 0.187 L 0.186 3.47 C 0.186 3.47 0 3.675 0 3.899 C 0 4.104 0.186 4.328 0.186 4.328 L 2.899 7.611 C 2.992 7.741 3.159 7.797 3.308 7.704 C 3.456 7.629 3.512 7.443 3.438 7.294 L 1.375 4.197 L 1.208 3.918 C 1.208 3.899 1.208 3.862 1.208 3.824 L 1.375 3.545 L 3.438 0.448 C 3.512 0.299 3.438 0.131 3.308 0.038 C 3.159 -0.037 2.992 0.001 2.899 0.131 Z" fill="rgb(255, 255, 255)" height="7.750209542168115px" id="Tb0_95onW" transform="translate(7.365 1.983)" width="3.470578512630766px"/><path d="M 0.026 1.94 C 0.1 2.07 0.249 2.108 0.379 2.052 L 2.832 0.97 C 2.85 0.97 2.869 0.97 2.887 0.97 L 5.34 2.052 C 5.47 2.108 5.619 2.052 5.693 1.94 C 5.768 1.809 5.731 1.66 5.6 1.585 L 3.222 0.112 C 3.222 0.112 3.036 0 2.869 0 C 2.664 0 2.497 0.112 2.497 0.112 L 0.119 1.585 C 0.007 1.66 -0.03 1.809 0.026 1.94 Z" fill="rgb(255, 255, 255)" height="2.07689008196461px" id="mLkmMllwc" transform="translate(3.029 9.724)" width="5.731234655014603px"/><path d="M 7.535 2.91 L 4.264 0.187 C 4.264 0.187 4.06 0 3.837 0 C 3.633 0 3.41 0.187 3.41 0.187 L 0.139 2.91 C 0.009 3.003 -0.047 3.171 0.046 3.32 C 0.12 3.469 0.306 3.525 0.455 3.451 L 3.54 1.38 L 3.818 1.212 C 3.837 1.212 3.874 1.212 3.911 1.212 L 4.19 1.38 L 7.275 3.451 C 7.423 3.525 7.591 3.451 7.684 3.32 C 7.758 3.171 7.721 3.003 7.591 2.91 Z" fill="rgb(255, 255, 255)" height="3.483478327665331px" id="r0d9h4JTL" transform="translate(2.06 7.392)" width="7.7215409515449345px"/><path d="M 0.137 0.026 C 0.007 0.1 -0.031 0.25 0.025 0.38 L 1.103 2.842 C 1.103 2.861 1.103 2.879 1.103 2.898 L 0.025 5.36 C -0.031 5.491 0.025 5.64 0.137 5.715 C 0.267 5.789 0.415 5.752 0.49 5.621 L 1.958 3.234 C 1.958 3.234 2.069 3.047 2.069 2.879 C 2.069 2.674 1.958 2.506 1.958 2.506 L 0.49 0.119 C 0.415 0.007 0.267 -0.03 0.137 0.026 Z" fill="rgb(255, 255, 255)" height="5.752526692867306px" id="yi3WcGLKq" transform="translate(0 3.04)" width="2.0691900389284807px"/><path d="M 0.572 7.6 L 3.285 4.318 C 3.285 4.318 3.471 4.112 3.471 3.889 C 3.471 3.683 3.285 3.46 3.285 3.46 L 0.572 0.14 C 0.479 0.009 0.312 -0.047 0.163 0.046 C 0.014 0.121 -0.042 0.307 0.033 0.457 L 2.095 3.553 L 2.263 3.833 C 2.263 3.851 2.263 3.889 2.263 3.926 L 2.095 4.206 L 0.033 7.302 C -0.042 7.451 0.033 7.619 0.163 7.712 C 0.312 7.787 0.479 7.749 0.572 7.619 Z" fill="rgb(255, 255, 255)" height="7.750215283552243px" id="p6XslZnAU" transform="translate(0.922 2.031)" width="3.4705880585442213px"/></g><path d="M 4.007 1.424 C 4.508 1.424 4.897 1.536 5.231 1.759 C 5.565 1.983 5.787 2.29 5.927 2.709 L 7.735 2.709 C 7.513 1.843 7.067 1.173 6.427 0.698 C 5.787 0.223 4.981 0 3.979 0 C 2.977 0 2.504 0.168 1.92 0.531 C 1.308 0.866 0.863 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.501 6.423 C 0.835 7.066 1.308 7.568 1.92 7.903 C 2.532 8.267 3.2 8.434 3.979 8.434 C 4.758 8.434 5.76 8.183 6.4 7.708 C 7.04 7.205 7.485 6.563 7.735 5.725 L 5.927 5.725 C 5.62 6.591 4.981 7.01 3.979 7.01 C 2.977 7.01 2.755 6.758 2.337 6.256 C 1.92 5.753 1.725 5.083 1.725 4.189 C 1.725 3.295 1.92 2.625 2.337 2.15 C 2.755 1.648 3.283 1.424 3.979 1.424 Z" fill="rgb(255, 255, 255)" height="8.434076339054002px" id="d2DNCsqwq" transform="translate(15.609 3.128)" width="7.735096310284753px"/><path d="M 6.093 0.503 C 5.481 0.168 4.814 0 4.034 0 C 3.255 0 2.532 0.168 1.92 0.531 C 1.308 0.866 0.835 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.529 6.423 C 0.89 7.066 1.363 7.568 1.976 7.903 C 2.588 8.267 3.283 8.434 4.062 8.434 C 4.841 8.434 5.815 8.183 6.455 7.708 C 7.095 7.233 7.54 6.619 7.791 5.865 L 5.982 5.865 C 5.62 6.619 4.98 7.01 4.062 7.01 C 3.144 7.01 2.894 6.814 2.476 6.423 C 2.031 6.032 1.809 5.502 1.753 4.859 L 7.958 4.859 C 7.985 4.608 8.013 4.329 8.013 4.022 C 8.013 3.24 7.846 2.541 7.512 1.927 C 7.179 1.313 6.706 0.838 6.121 0.503 Z M 1.725 3.491 C 1.809 2.849 2.059 2.346 2.476 1.983 C 2.894 1.62 3.395 1.424 3.979 1.424 C 4.563 1.424 5.147 1.62 5.593 1.983 C 6.038 2.346 6.26 2.849 6.26 3.491 L 1.753 3.491 Z" fill="rgb(255, 255, 255)" height="8.434076339054002px" id="NZQSgmK3B" transform="translate(24.013 3.128)" width="8.01332295195354px"/><path d="M 5.815 0.391 C 5.314 0.112 4.73 0 4.09 0 C 3.45 0 3.144 0.084 2.727 0.279 C 2.309 0.475 1.948 0.726 1.669 1.061 L 1.669 0.14 L 0 0.14 L 0 8.294 L 1.669 8.294 L 1.669 3.742 C 1.669 3.016 1.864 2.458 2.226 2.067 C 2.587 1.676 3.088 1.48 3.729 1.48 C 4.368 1.48 4.841 1.676 5.231 2.067 C 5.592 2.458 5.787 3.016 5.787 3.742 L 5.787 8.294 L 7.457 8.294 L 7.457 3.491 C 7.457 2.737 7.318 2.122 7.04 1.592 C 6.761 1.061 6.344 0.67 5.843 0.419 Z" fill="rgb(255, 255, 255)" height="8.294435702953454px" id="y4C5qOSA0" transform="translate(33.166 3.128)" width="7.4567073744807075px"/><path d="M 2.643 0 L 0.946 0 L 0.946 2.039 L 0 2.039 L 0 3.407 L 0.946 3.407 L 0.946 7.931 C 0.946 8.741 1.141 9.3 1.558 9.663 C 1.948 10.026 2.532 10.193 3.311 10.193 L 4.647 10.193 L 4.647 8.797 L 3.617 8.797 C 3.283 8.797 3.033 8.741 2.894 8.602 C 2.755 8.462 2.671 8.239 2.671 7.931 L 2.671 3.407 L 4.647 3.407 L 4.647 2.039 L 2.671 2.039 L 2.671 0 Z" fill="rgb(255, 255, 255)" height="10.193494685087567px" id="HConpA1k2" transform="translate(41.458 1.229)" width="4.646524285330045px"/><path d="M 1.085 0 C 0.779 0 0.528 0.112 0.306 0.307 C 0.111 0.503 0 0.782 0 1.089 C 0 1.396 0.111 1.648 0.306 1.871 C 0.501 2.095 0.779 2.178 1.085 2.178 C 1.391 2.178 1.642 2.067 1.836 1.871 C 2.031 1.676 2.142 1.396 2.142 1.089 C 2.142 0.782 2.031 0.531 1.836 0.307 C 1.642 0.112 1.391 0 1.085 0 Z" fill="rgb(255, 255, 255)" height="2.1783368721996954px" id="EuoH5GVjb" transform="translate(47.384 0)" width="2.1424521645366994px"/><path d="M 1.669 0 L 0 0 L 0 8.155 L 1.669 8.155 Z" fill="rgb(255, 255, 255)" height="8.154788300335934px" id="zg308Vtf3" transform="translate(47.607 3.267)" width="1.6694896185170123px"/><path d="M 1.085 0 C 0.779 0 0.529 0.112 0.306 0.307 C 0.111 0.503 0 0.782 0 1.089 C 0 1.396 0.111 1.648 0.306 1.871 C 0.501 2.067 0.779 2.178 1.085 2.178 C 1.391 2.178 1.642 2.067 1.836 1.871 C 2.031 1.676 2.142 1.396 2.142 1.089 C 2.142 0.782 2.031 0.531 1.836 0.307 C 1.642 0.112 1.391 0 1.085 0 Z" fill="rgb(255, 255, 255)" height="2.1783368721996954px" id="SaMxhxR35" transform="translate(55.842 0)" width="2.1424521645367136px"/><path d="M 4.007 7.01 C 3.311 7.01 2.783 6.758 2.365 6.256 C 1.948 5.753 1.753 5.083 1.753 4.189 C 1.753 3.295 1.948 2.625 2.365 2.15 C 2.783 1.648 3.311 1.424 4.007 1.424 C 4.702 1.424 4.897 1.536 5.231 1.759 C 5.565 1.983 5.788 2.29 5.926 2.709 L 7.735 2.709 C 7.513 1.843 7.067 1.173 6.427 0.698 C 5.788 0.223 4.981 0 3.979 0 C 2.977 0 2.504 0.168 1.92 0.531 C 1.308 0.866 0.862 1.368 0.501 2.011 C 0.167 2.653 0 3.379 0 4.217 C 0 5.055 0.167 5.809 0.501 6.423 C 0.835 7.066 1.308 7.568 1.92 7.903 C 2.532 8.267 3.2 8.434 3.979 8.434 C 4.758 8.434 5.76 8.183 6.4 7.708 C 7.04 7.205 7.485 6.563 7.735 5.725 L 5.926 5.725 C 5.621 6.591 4.981 7.01 3.979 7.01 Z" fill="rgb(255, 255, 255)" height="8.434076339054002px" id="HetImuuV4" transform="translate(59.265 3.128)" width="7.735226155870485px"/><path d="M 6.872 3.268 L 2.643 3.268 L 2.643 2.681 C 2.643 2.206 2.754 1.871 2.949 1.676 C 3.144 1.508 3.478 1.396 3.923 1.396 L 3.923 0 C 2.921 0 2.17 0.223 1.697 0.642 C 1.196 1.061 0.946 1.759 0.946 2.681 L 0.946 3.268 L 0 3.268 L 0 4.636 L 0.946 4.636 L 0.946 11.422 L 2.643 11.422 L 2.643 4.636 L 5.203 4.636 L 5.203 11.422 L 6.872 11.422 Z" fill="rgb(255, 255, 255)" height="11.422308710362525px" id="Xc4NeSznw" transform="translate(50.863 0)" width="6.872402238697973px"/></g></svg>)


4 min read time
Topics

Centific
Multilingual instruction tuning and safety alignment require high-quality, diverse training data. But collecting that data, especially for low-resource languages and sensitive topics like privacy or misuse, remains slow, expensive, and inconsistent.
In our VLDB 2025 paper, we have introduced AI-assisted annotation, a scalable human-in-the-loop framework that combines prompt writers, quality assurance based on large language models (LLMs), and synthetic personally identifiable information (PII) tools to accelerate multilingual prompt generation. By using LLMs not just as generators, but as judges, we have reduced annotation time by over 40% without sacrificing coverage, quality, or instruction compliance.
We deployed AI-assisted annotation to create more than 40,000 high-quality prompts across 13 languages, covering tasks like personal data redaction, safety alignment, and misuse detection. Those are all critical areas for LLM safety evaluation.
The challenge: scaling prompt writing for low-resource locales
Instruction tuning and safety alignment depend on training data that reflects realistic, nuanced user inputs. For high-stakes applications like identifying harmful intent or protecting personal data, researchers often rely on human-written prompts to capture edge cases and ambiguity. But this manual work doesn’t scale, especially when:
Prompts must be written in underrepresented languages
They must include synthetic but realistic PII
They must follow complex, high-precision instructions
And they must avoid repetition while maintaining natural variation
Manual workflows struggle to meet all these constraints at scale, making it difficult to build multilingual safety datasets that are both broad and reliable.
The framework: AI-augmented prompt generation with LLM-as-a-judge
AI-assisted annotation introduces a modular, AI-supported pipeline to improve throughput, quality, and diversity in human-authored prompts. The system includes:
Synthetic PII Suggestion: we recommend structured, locale-specific PII—like Aadhaar numbers or health IDs— using a tool that draws from curated templates and fake data generators.
LLM-as-a-judge for instruction following: instead of using LLMs to write prompts, we use them to evaluate and score human-written ones. Judges assess instruction of compliance (e.g., word count, structure, content type) and provide instant feedback to writers.
Similarity checking: We apply vector-based checks to flag lexically or semantically repetitive prompts, enforcing diversity across submissions.
Maintaining Data Diversity: As LLM training would require good coverage and diversity of input data, authors are provided with structured guidance on domain, PII type combinations, text length.
Unlike traditional pipelines, AI-assisted annotation delivers immediate feedback loops, reducing rework and improving consistency across annotators and languages.
Deployment at scale: 13 languages, 40,000+ prompts
We deployed AI-assisted annotation with Centific’s professional annotation teams to generate multilingual prompts across 13 locales: Arabic (UAE), Finnish (Finland), Hindi (India), Norwegian (Norway), Dutch (Belgium), Dutch (Netherlands), Polish (Poland), Portuguese (Brazil), Portuguese (Portugal), Swedish (Sweden), Vietnamese (Vietnam), and Chinese (China), Chinese (Singapore).
Each prompt was written by a human, guided by tools and judged by an LLM for accuracy and coverage. Prompts were designed to simulate:
Domain (e.g., IT, CPG, Healthcare, Finance)
Requests containing region-specific PII (e.g., local ID numbers, bank account formats)
Malicious or ambiguous intent (e.g., phishing, scams)
Natural language diversity (e.g., tone, phrasing, cultural context)
Task category (summarization, rewrite, translation, chain-of-thought)
Tasks included redaction, classification, and detection of misuse, aligned with the needs of LLM safety benchmarks.
Results: 40% faster, with no drop in quality
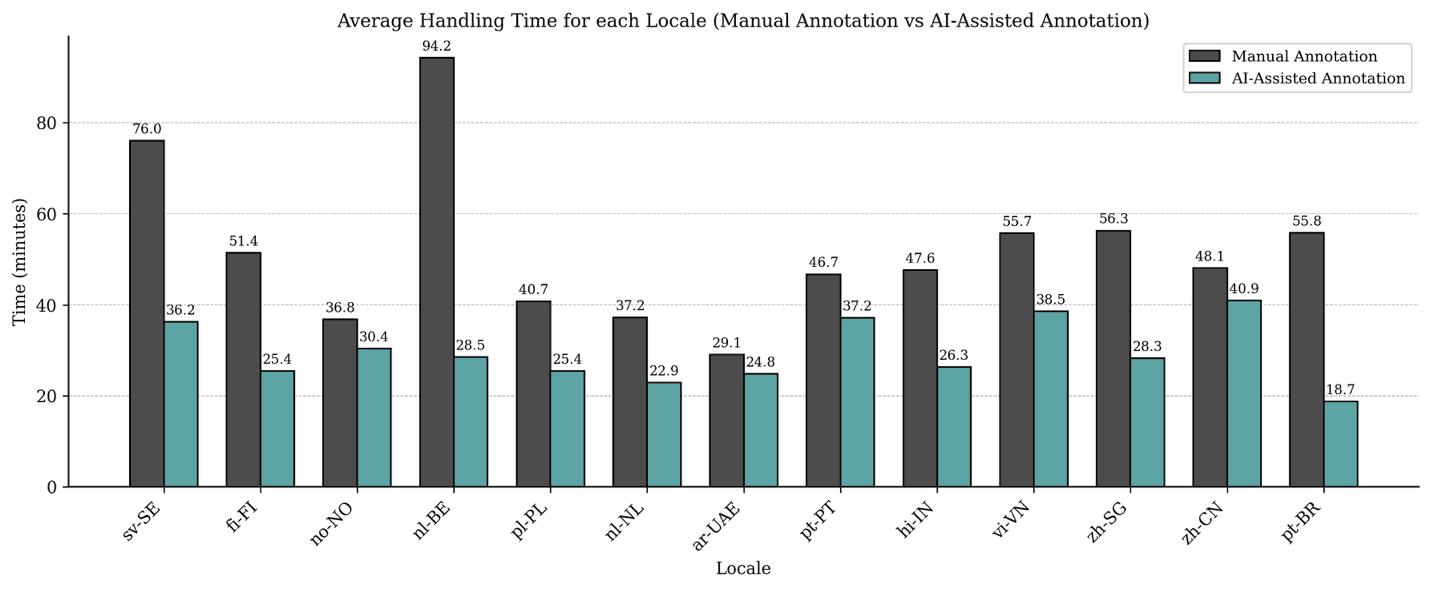
We ran a comparative study of AI-assisted annotation against a traditional human-only workflow. Key results:
40% reduction in average handling time per prompt, driven by fewer revision cycles and better real-time feedback.
Significant gains in instruction compliance, especially word count, PII formatting, and language specificity.
Higher lexical and structural diversity, enforced through AI-based repetition checks.
These gains did not come at the cost of quality: judged correctness, completeness, and naturalness of prompts were statistically equivalent across workflows.
Why it matters
AI-assisted Annotation addresses a known bottleneck in LLM alignment: scalable, high-quality prompt generation in underrepresented languages. The framework:
Improves multilingual coverage for red-teaming, safety tuning, and PII detection
Reduces annotation cost without losing linguistic or structural diversity
Provides a reusable pipeline that supports multilingual model evaluation and instruction tuning
By decoupling prompt generation from manual review, and using LLMs as real-time QA agents, we improve both speed and safety in data creation.
What’s next
We are expanding AI-assisted annotation to support longer tasks, multi-turn dialogue, and complex chain-of-thought reasoning prompts. Future work includes evaluating LLM-as-a-judge alignment with human quality scores and extending the framework to unseen languages and scripts.
Are your ready to get
modular
AI solutions delivered?
Connect data, models, and people — in one enterprise-ready platform.
Latest Insights



Connect with Centific
Updates from the frontier of AI data.
Receive updates on platform improvements, new workflows, evaluation capabilities, data quality enhancements, and best practices for enterprise AI teams.