Grok 4 raises the AI benchmark—imperfectly
Categories
xAI
Grok 4
Gen AI
Reinforcement learning
Share

xAI made one of the biggest announcements in the AI world this year with the release of Grok 4. Elon Musk called it “the smartest AI in the world” and claimed its intelligence rivals that of “almost all graduate students in all disciplines simultaneously.”
After watching the livestream and reviewing the benchmarks, I believe the excitement is justified overall. At the same time, controversy has erupted due to Grok sharing inappropriate and harmful content, raising questions about the safety and reliability of the model. This moment captures a core tension in the AI race: as companies sprint toward superintelligence, they must balance speed, quality, and safety.

Grok 4’s benchmark wins prove its scale and reasoning power
Grok 4 is a flex on the AI world, dominating benchmarks and making advanced reasoning feel effortless. xAI matched pre-training compute with post-training reinforcement learning, which is a major move for transforming raw data into real logic.
It’s also relatively affordable: $3/M input tokens, $15/M output tokens, with a 256k context window that doubles beyond 128k.
Grok is already available via API through xAI, though access is still limited to X for integrations and select use cases, not a public playground model like GPT or Claude.
Early signs point toward multimodal capability as well. Grok 4 can already generate 3D assets using tools like .urdf files for robotics or gaming applications.
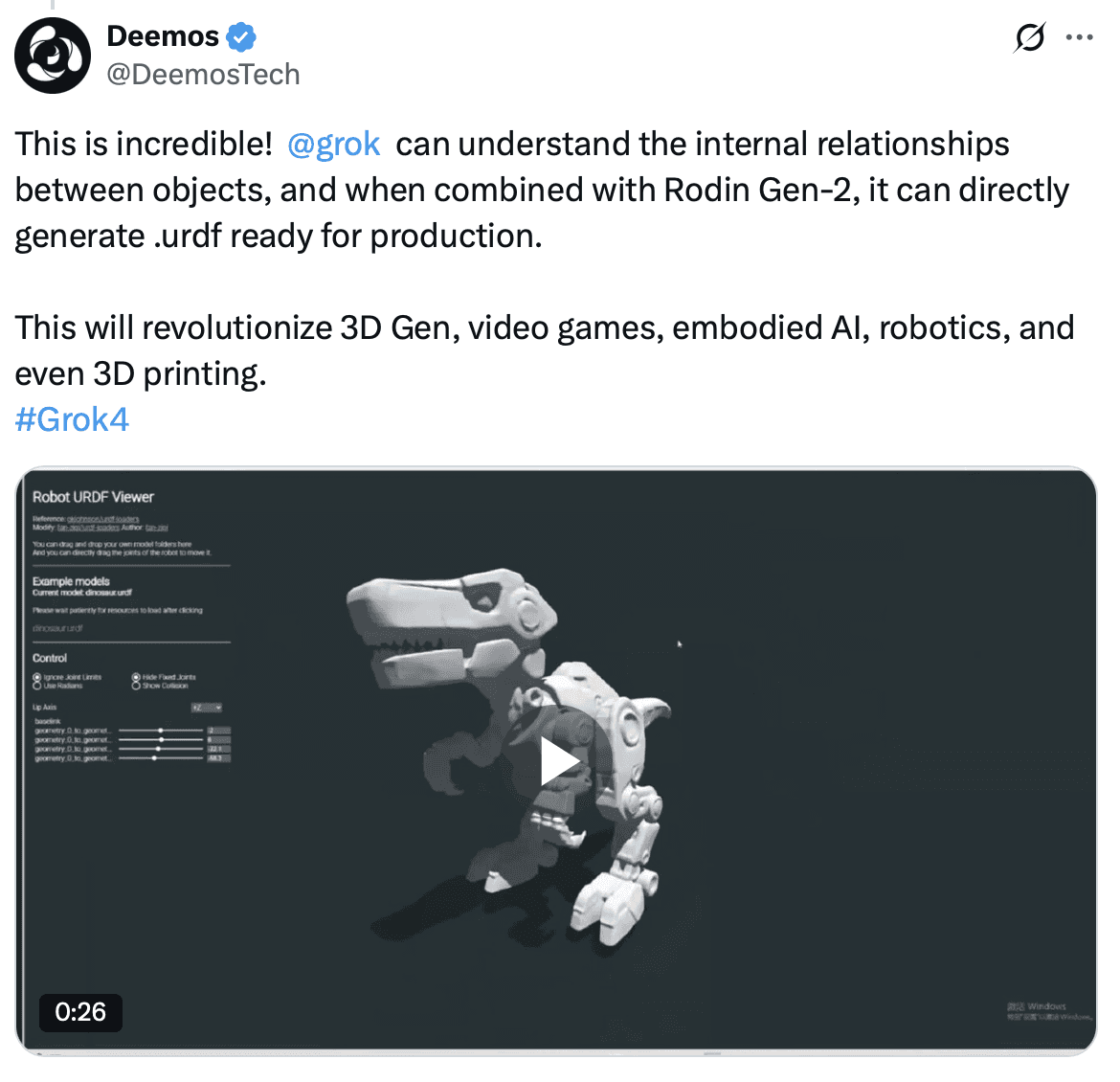
Grok 4 was released alongside Grok 4-Heavy, a higher-capacity variant that trades off speed for more power. While the base model is optimized for responsiveness, the heavy version is intended for more demanding tasks, offering developers flexibility depending on their needs.
Check the benchmarks: Grok 4 tops the charts in reasoning, math, and coding. It’s been called “PhD-level across every subject.” Certainly X users are taking note.
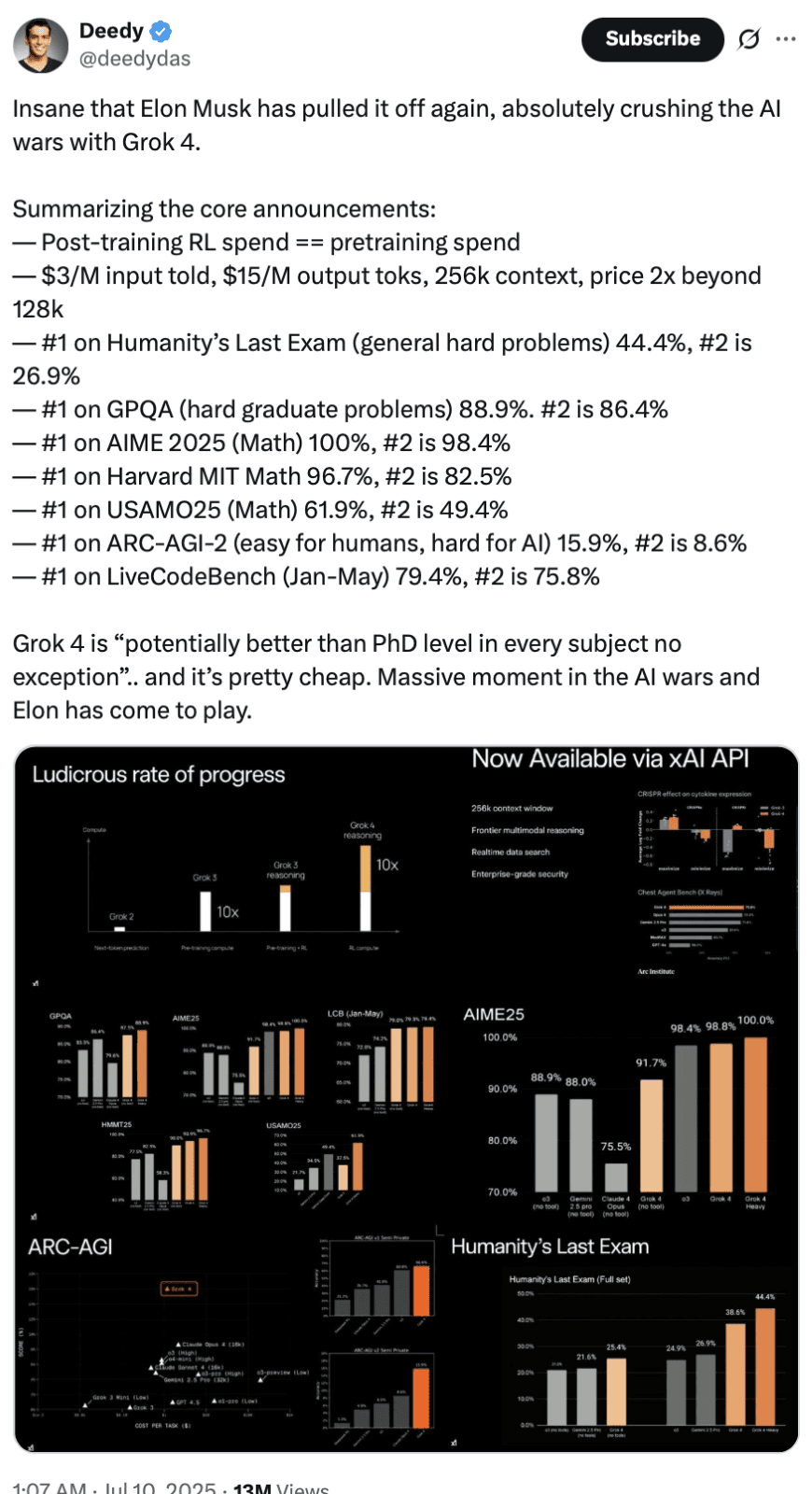
Here’s a quick breakdown of how it stacks up:

The standout here is Humanity’s Last Exam, a benchmark designed to measure general intelligence across a wide range of topics with minimal prompting. Grok 4’s lead over the second-best model is massive, and symbolic. It supports xAI’s claim that Grok approaches graduate-level intelligence across disciplines.

That ARC-AGI jump also suggests breakthroughs in fluid intelligence. Thanks to reinforcement learning baked into training from the ground up, Grok 4 behaves less like a memorizer and more like a problem-solver. Unlike most LLMs, where RL is tacked on during fine-tuning, Grok 4 is RL-native, making reinforcement learning a core part of both training and inference behaviors.
It’s already being positioned for agentic applications, supporting tool use and robust reasoning without excessive censorship, something xAI continues to prioritize.
xAI scaled up with expert input, massive compute, and reinforcement learning
From team posts, it’s clear xAI went all-in on infrastructure: 200k-GPU clusters, 100x compute scaling, higher-quality data curation, RL-native pipelines, and robust training recipes. As Shengyang Sun of xAI put it: “That’s how you turn RL into the pre-training scale.” Matching RL spend with pre-training spend is the secret behind the benchmark leaps.
Latency also got serious attention. Grok 4’s inference speed and infrastructure stability have been significantly improved to support real-world use cases, including automotive-grade deployments. That performance edge matters when you’re talking about Tesla integration or agentic tools running in production.

The team likely tapped domain experts—researchers like Yuhuai Wu and Eric Zelikman—to curate specialized datasets in math, coding, and reasoning. HITL (human-in-the-loop) feedback likely played a big role in reinforcement learning from human feedback (RLHF), refining Grok’s performance on advanced tasks like GPQA and USAMO.
Curation mattered, too. Using high-quality data sources prevented the “garbage-in, garbage-out” problem.
Red-teaming was likely in play during training, given the robustness and openness of Grok 4’s responses. It’s a textbook case of blending deep human expertise with massive compute, an approach I’ve seen evolve firsthand over 20+ years building AI systems.
An imperfect launch or the reality of launching a model quickly?
Grok 4’s technical rollout was impressive overall, but Grok was also flagged for producing racist, biased, and harmful outputs, causing immediate scrutiny. Grok’s problematic responses highlight a critical balance: raw intelligence alone isn’t sufficient, and while Musk promoted Grok’s uncensored outputs as a strength, these incidents demonstrate the risks of launching models with speed and the need for grounding, alignment and safety (ala proper red teaming; see our recent partnership with VirtueAI).
This controversy highlights the importance of red-teaming—the systematic testing of AI model vulnerabilities—to identify biases, vulnerabilities, and harmful behaviors. To restore user trust and mitigate risks, many are calling on xAI to urgently strengthen its red-teaming practices. Collaborating with independent, diverse experts trained to proactively challenge models can significantly reduce future harm.
The roadmap shows promise and reveals important gaps

The roadmap depicted on the livestream says a lot. Grok 4 is out now (July), with a Coding Model planned for August, a Multi-modal Agent for September, and a Video Generation Model coming in October.
That sequence reveals some important areas for growth. Grok 4 supports text and some image generation, but full multimodal capabilities, like audio and video comprehension, aren’t live yet. Advanced coding tasks and deep engineering aren’t fully addressed either, suggesting the upcoming Coding Model will go deeper in those areas.
Agentic capabilities are also in progress. The September agent model implies that tool+vision integration is still being built out. And since text-to-video generation doesn’t arrive until October, creative and simulation use cases remain limited for now.
Elon Musk also announced that Grok 4 is rolling out to 5+ million Tesla vehicles within days. That means a real-time flood of datasets from onboard cameras, audio, and environmental queries. As a Tesla owner, I’m excited to test it.
This scale introduces challenges: real-time multimodal processing, privacy protection, and safety-grounded red-teaming are critical. Grok will need to handle global languages, accents, and edge cases without introducing hallucinations or failures in navigation.
That rollout is already sparking speculation about how Grok 4 could shape the future of autonomous driving and simulation. One recent X post by patent researcher @seti_park ties Grok 4 to Tesla’s new patent (US20240378899A1) for simulated vision training. The idea: use Grok to generate photorealistic, physics-accurate edge cases for full self-driving simulations.
That could push Tesla’s reinforcement learning training beyond real roads and into simulated scenarios, faster and safer. But it raises questions: Will simulated data introduce bias? Can Grok maintain safety in virtual training environments? October’s video model release will be pivotal here.
But between now and then, Grok 4 is certainly impressing the X community.

Centific can help fill the gaps with expert-driven support
At Centific, we’re built to help close critical gaps in Grok’s development, like expanding multimodal capabilities, fine-tuning specialized coding skills, red-teaming for safety, and preparing Grok for large-scale real-world deployment in Tesla vehicles.
Our domain expert pool includes PhDs in reasoning, bio, and coding, all ready to contribute human feedback and domain knowledge to accelerate Grok’s roadmap milestones, whether that’s the August Coding Model or the September multimodal agent.
We support 90+ languages and cultures, which will be critical for Tesla’s worldwide user base. We also red-team AI systems across use cases, simulating jailbreaks and adversarial inputs to reduce risk. For multimodal models, we add context across text, image, video, and audio to reduce hallucinations and keep output grounded.
If Grok 4 is about to power full self-driving simulations, we can help there, too. Our teams build hybrid datasets by blending real-world data with simulated inputs, then run HITL and adversarial loops to train models that are both smart and safe.
We’ve spent decades helping global AI systems move from prototype to production, and we’re ready to help Grok do the same.
Grok 4: let’s help Grok go further, safely
Grok 4 is undeniably powerful, but its launch also underscores a vital lesson: technical brilliance must go hand in hand with robust safety measures. I am curious to know what you think of the launch, the controversy, and Grok’s future. Let’s discuss.

Trevor Legwinski is a technology alliances and product development leader with more than 18 years of experience driving revenue growth and product innovation. At Centific, he helps organizations scale GenAI solutions through a flexible, integrated ecosystem spanning data, fine-tuned models, RAG pipelines, SafeAI practices, and emerging applications like AI-driven supply chains. Trevor has led teams across product, marketing, customer success, and sales, launching six SaaS AI platforms, 20 predictive apps, and enabling AI adoption for more than 50 brands and 100,000 developers worldwide.
Categories
xAI
Grok 4
Gen AI
Reinforcement learning
Share