We’re grading AI on puzzles, not real work. It's time for a change
Jan 12, 2026
Categories
AI Research
Code Generation
LLM Evaluation
AI Benchmarks
Software Engineering
Share

Would you hire a software engineer based solely on their performance solving logic puzzles? Most certainly not. This would be an incomplete test at best. Someone might excel at whiteboard exercises and still struggle when faced with a real production system: a sprawling codebase, years of accumulated decisions, legacy dependencies, business rules, security constraints, and the realities of working inside a team.
But this is effectively how the AI industry evaluates code generation models today. Despite rapid progress in AI-assisted coding, most benchmarks still focus on small, artificial problems that resemble academic exercises rather than real software development. Models appear highly capable on paper yet often fall short when deployed inside enterprise environments. The result is a widening gap between benchmark performance and practical usefulness.
This article examines why today’s benchmarks fail to reflect real-world development, how that failure distorts progress and adoption, and why evaluation must shift toward private, repository-based benchmarks grounded in actual enterprise code. Through analysis of 18+ major benchmarks, the Centific AI Research team identifies universal gaps in real-world alignment and proposes a private repository-based evaluation as a comprehensive solution.
The current state of code generation evaluation
To understand the problem, it helps to look at how most AI coding tools are evaluated today.
Popular benchmarks ask models to complete isolated programming tasks, often limited to a single function or file. These tasks are easy to distribute, score, and compare, which is why they have become the industry standard. But they also remove the very context that defines real software development.
BigCodeBench, one of the most comprehensive benchmarks available today, evaluates large language models (LLMs) on 1,140 programming tasks that challenge models to invoke multiple function calls from 139 libraries across 7 domains¹. While this represents a significant step forward from earlier benchmarks, a deeper analysis reveals systemic limitations shared across the entire landscape of code generation evaluation.
A comprehensive look at current benchmark limitations
The landscape of code generation evaluation includes dozens of benchmarks, each attempting to measure different aspects of LLM coding capability. However, a systematic analysis of 18 major benchmarks reveals consistent patterns of limitations that collectively prevent accurate assessment of real-world coding performance.
The artificial task epidemic
Many benchmarks rely on problems that are carefully constructed to be solvable in isolation. This section examines how those task designs limit their usefulness.
HumanEval and its derivatives
HumanEval's 164 hand-crafted problems focus on "language comprehension, algorithms, and simple mathematics, with some comparable to simple software interview questions"², but these LeetCode-style challenges fail to represent actual software development scenarios.
Beyond single functions
ClassEval revealed that "all existing LLMs show much worse performance on class-level code generation compared to on standalone method-level code generation"³ with only 100 class-level Python tasks taking 500 person-hours to construct. Even this expanded scope remains artificially constrained.
Benchmark proliferation without innovation
Many benchmarks simply extend HumanEval's approach—CRUXEval provides 800 Python functions using "Code Llama 34B to generate a large set of functions"⁴, creating synthetic rather than real-world problems, while EvoEval shows that "popular LLMs significantly drop in performance (on average drop ~39.6% (varies by models/tasks)"⁵ when problems are evolved, suggesting overfitting to the original benchmark.
These benchmarks are useful for studying narrow capabilities, but they reward pattern recognition over real-world reasoning. As a result, they create the illusion of progress without ensuring applicability to enterprise software.
The data contamination crisis
Beyond task design, benchmark validity is undermined by contamination between training and evaluation data.
Widespread training data leakage
Studies have identified "8-18% of the HumanEval benchmark overlaps" with pre-training datasets like RedPajama-Data-1T and StarCoder-Data⁶. This contamination extends far beyond simple overlap—contamination can "cross language barriers" and is found even in "synthetic dataset generated by GPT-3.5/4"⁷.
The contamination arms race
LiveCodeBench attempts to address this by "continuously collecting new problems over time from contests across three competition platforms"⁸ published between May 2023 and May 2024; later leaderboard snapshots add newer problems. But this reactive approach cannot keep pace with training data collection.
Benchmark overfitting
Evidence shows "possible overfitting on HumanEval" where "models that perform well on HumanEval do not necessarily perform well on LiveCodeBench"⁸, indicating that high benchmark scores don't translate to real-world capability.
Contamination inflates scores and undermines trust. When benchmarks leak into training data, they stop measuring reasoning ability and start measuring recall.
The context complexity gap
Software development is rarely about isolated code fragments. This section highlights how benchmarks fail to capture the complexity of real repositories.
Single-file limitations
Most benchmarks focus on isolated functions or single files. CrossCodeEval addresses how "existing code completion datasets such as HumanEval and MBPP mostly focus on single-file tasks, neglecting the real-world complexity of multi-file software projects"⁹, while TabbyML's analysis shows that "HumanEval includes mostly LeetCode's interview-style questions, where they include a single function for LLMs to fill in the body" while "developers often add code in multiple files in a single PR"¹⁰.
Repository-level challenges
ExecRepoBench found that "evaluation in repository-level multilingual scenario is not fully explored" and existing benchmarks using "exact match and edit similarity without code execution cannot accurately reflect the model performance"¹¹.
Without repository context, models are tested on tasks that strip away dependencies, architectural decisions, and historical constraints that define real systems.
Enterprise reality vs. benchmark fantasy
The gap between benchmarks and enterprise reality becomes most visible when models are tested against real business workflows.
Simplified problem domains
NaturalCodeBench reports a mismatch with HumanEval —many benchmarks skew toward introductory algorithm/data-science tasks¹². Spider 2.0—a Text-to-SQL benchmark focused on schema generalization and compositional SQL, scored by execution accuracy—shows the real gap: enterprise databases can be large and heterogeneous, and even advanced models like o1-preview solve only 21.3% of Spider 2.0 tasks (vs. 91.2% on Spider 1.0) ¹³.
Missing enterprise complexity
DevBench attempts to address this with "multi-file codebase starting from a product requirement document" but models still "struggle with understanding the complex structures in the repository, managing the compilation process, and grasping advanced programming concepts"¹⁴.
When evaluation begins to resemble enterprise conditions, benchmark performance collapses. This is not a failure of models alone. It is a failure of evaluation assumptions.
Evaluation methodology flaws
Even when tasks are reasonably constructed, evaluation methods often fall short. This section focuses on how scoring approaches themselves obscure real capability.
Weak test coverage
Test cases in HumanEval tasks "(on average 7.7 tests per problem) aren't enough to guarantee the correctness of the generated code"¹⁰, leading to false positives where broken code passes limited tests.
Metric limitations
TabbyML's research shows that "HumanEval pass@1 as a code completion benchmark" has significant limitations, leading them to embrace "Next Line Accuracy as a metric" instead¹⁰. Many benchmarks focus solely on functional correctness without considering code quality, maintainability, or security.
When metrics focus only on whether code runs once, they ignore whether it should exist at all. Enterprises need signals about robustness, safety, and long-term cost.
Visualizing the benchmark coverage gap
To understand the scope of these limitations, the Centific AI Research team analyzed how different benchmarks perform across critical evaluation dimensions. The following analysis shows the coverage patterns of major benchmarks across eight key dimensions that matter for real-world software development.
Real-world alignment - How well tasks mirror actual development scenarios
Enterprise relevance - Applicability to business software development
Cross-file dependencies - Requirements for multi-file understanding
Repository complexity - Scale and interconnectedness needed
Contamination resistance - Protection from training data leakage
Domain specificity - Industry-specific patterns and requirements
Collaborative context - Team development scenarios
Problem complexity - Technical sophistication required
Methodology note: the scores represent analytical synthesis of qualitative evidence from research papers, not empirical measurements. Each benchmark was scored 1-5 across eight dimensions based on documented characteristics and limitations.
Benchmark performance summary
Benchmark Evaluation on 8 Key Dimensions (1-5 Scale). Please see the appendix for more detail.
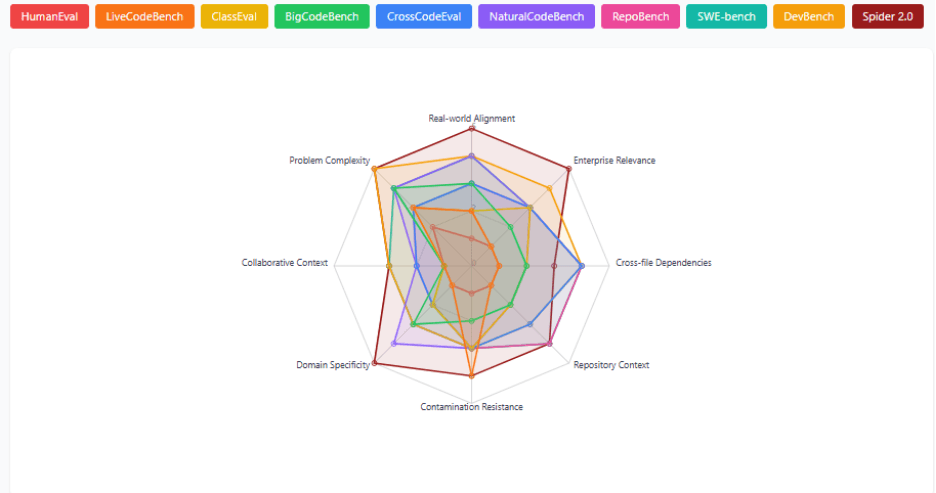
The benchmark analysis reveals a consistent pattern: the closer an evaluation comes to real software development, the more existing models struggle. High scores tend to reflect benchmark familiarity rather than readiness for enterprise conditions.
Universal gap: Collaborative Context averages only 1.7/5.0 across all benchmarks
Worst performer: HumanEval scores 1-2 across all real-world dimensions
Best existing: Spider 2.0 (4.25 avg) excels in enterprise relevance and domain specificity
These results suggest that benchmark success today is a weak proxy for practical usefulness. The industry is measuring what is easy to score, not what is costly to fail in production.
Lowest performers (average scores 1.1-1.75/5)
The lowest-performing benchmarks share a common trait: they rely heavily on isolated, synthetic tasks that remove context, dependencies, and operational constraints. As a result, they offer little insight into how models perform in real development environments.
HumanEval: 1.1/5 - Scores 1-2 across all dimensions, representing the most artificial benchmark
EvoEval: 1.5/5 - Academic problem transformations without real-world grounding
LiveCodeBench: 1.75/5 - Only strong in contamination resistance (4/5)
While these benchmarks are useful for controlled experimentation, they systematically overstate real-world capability. Their low scores across enterprise-relevant dimensions explain why benchmark gains often fail to translate into deployment success.
Medium performers (Average scores 2.6-3.5/5)
Benchmarks in the middle tier begin to incorporate elements of real software work, such as repository context or natural user prompts. However, they still stop short of capturing the full complexity of enterprise development.
SWE-bench: 3.5/5 - Strong repository complexity and cross-file dependencies
NaturalCodeBench: 3.0/5 - Good real-world alignment from user queries
CrossCodeEval: 2.6/5 - Focused on cross-file dependencies but artificial construction
These benchmarks point in the right direction but remain incomplete. They expose meaningful weaknesses in current models, yet they lack the business logic, collaboration patterns, and operational constraints that define real production systems.
Highest existing performer
Spider 2.0 stands apart because it is explicitly grounded in enterprise workflows rather than abstract coding tasks. Its design choices make failure visible where it actually matters: complex, real-world use cases.
Spider 2.0: 4.3/5 - Excels in enterprise relevance (5/5) and domain specificity (5/5)
Spider 2.0’s stronger alignment with enterprise reality coincides with sharply lower model performance. This reinforces a central theme of the analysis: realism reveals capability gaps that simpler benchmarks hide.
Universal coverage gaps identified
Several deficiencies appear consistently across all benchmarks, regardless of task type or scoring method. These gaps reflect what benchmarks systematically omit rather than what models inherently lack.
Collaborative context: Average 1.7/5 across all existing benchmarks
Cross-file dependencies: Average 2.3/5 across all existing benchmarks
Enterprise relevance: Average 2.4/5 across all existing benchmarks
Contamination resistance: Average 2.9/5 across all existing benchmarks
These missing dimensions explain why benchmark results often fail to predict enterprise outcomes. Until evaluation reflects how software is actually built, tested, and maintained, performance scores will remain misleading.
Bottom line: benchmarks that most resemble real work expose the largest performance gaps. Benchmarks that produce the highest scores are the least representative. This tension sits at the heart of the industry’s evaluation problem and underscores the need for a fundamentally different approach.
The missing piece: what real development looks like
The analysis of 18+ benchmarks reveals a systematic gap between evaluation scenarios and actual software development. Consider what professional development involves versus what current benchmarks test:
Repository-level understanding vs. single-file tasks
Real coding requires understanding relationships across multiple files, tracing dependencies through different services, and grasping architectural patterns that span entire repositories. Current benchmarks largely ignore this reality—SWE-bench attempts repository-level evaluation but focuses on isolated GitHub issues rather than integrated development workflows¹⁵.
Related repo-level suites
SWE-bench (≈2.2k issues across 12 Python repos) evaluates end-to-end bug-fixing with containerized environments. SWE-bench Verified provides ~500 human-validated tasks; SWE-bench-Live continuously refreshes tasks to mitigate contamination. These complement our private-repo direction by demonstrating executable, repo-scale evaluation and the importance of frozen snapshots and deterministic environments.
Enterprise workflows vs. academic problems
Enterprise development involves complex business logic, integration with existing systems, and adherence to organizational standards. Spider 2.0's finding that models achieve only 21.3% success on real enterprise database workflows, compared to 91.2% on Spider 1.0, illustrates this gap dramatically¹³.
Domain-specific patterns vs. generic solutions
Enterprise codebases contain domain-specific patterns, conventions, and architectural decisions that are rarely found in public repositories. A financial services company's codebase will have different patterns than a gaming company's, and both will differ significantly from open-source projects.
Collaborative development vs. isolated problem solving
Real-world software development involves:
Code reviews and collaboration patterns that require understanding team conventions
Legacy integration where new code must work with existing, sometimes poorly documented systems
Incremental development where changes build upon previous work
Business context where technical decisions must align with organizational goals
These dynamics define how software is actually built in organizations, yet they remain largely absent from most code generation benchmarks.
The private repository solution: addressing systemic limitations
The limitations identified across existing benchmarks are systemic. Addressing them requires a different foundation for evaluation, grounded in real software development environments rather than synthetic or academic abstractions.
The solution to these pervasive limitations lies in applying private repository data to create more realistic, contamination-free benchmarks. This approach directly addresses the fundamental problems identified across all major benchmarks:
Elimination of contamination issues
Private, access-controlled repos substantially reduce contamination risk. Benchmarks created from private repos should enforce no-train-on-evals agreements, rotating hidden splits, and near-duplicate detection to further mitigate leakage.
Without credible separation between training and evaluation data, benchmark results lose their meaning. Contamination-resistant evaluation restores confidence that measured performance reflects real generalization rather than memorization.
Real-world complexity and context
Private repositories introduce the kinds of complexity that public benchmarks routinely abstract away. They reflect how software is actually built and maintained inside organizations, where code is shaped by existing architectures, business logic, and operational constraints. This context is essential for evaluating whether AI can function reliably within real development environments rather than isolated test cases.
Multi-file dependencies
Unlike CrossCodeEval's artificially constructed scenarios, private repositories contain genuine architectural relationships where understanding one component requires knowledge of many others.
Enterprise-scale challenges
Address Spider 2.0's finding that models fail on real enterprise workflows by providing authentic database schemas, business logic patterns, and integration requirements.
Domain-specific patterns
Move beyond NaturalCodeBench's "introductory tasks" to include industry-specific patterns, regulatory compliance requirements, and business domain knowledge.
Enterprise software is defined by context. Benchmarks that remove that context inevitably overstate capability.
Authentic development scenarios
Beyond code structure, private repositories capture how software actually evolves over time. They reflect the accumulation of incremental changes, design trade-offs, and revisions driven by real business needs rather than idealized requirements. This longitudinal context is critical for evaluating whether AI can support ongoing development, not just produce correct code in isolation.
Collaborative context
Instead of ClassEval's isolated class generation or BigCodeBench's tool-use scenarios, private repository data provides real examples of how code evolves through team collaboration, code reviews, and iterative development.
Legacy integration
Address DevBench's limitation where models "struggle with understanding the complex structures in the repository" by providing authentic legacy integration scenarios that developers actually face.
Business-driven development
Move beyond EvoEval's academic problem transformations to include real requirements, constraints, and trade-offs that shape enterprise development decisions.
Most enterprise development work is incremental and collaborative. Benchmarks that ignore this dimension fail to reflect how AI will be used in practice.
Comprehensive task diversity
Private repositories enable a broader and more realistic range of evaluation tasks. They allow benchmarks to reflect the variety of work engineers actually perform, from extending existing features to modifying infrastructure and maintaining integrations across systems. This diversity is essential for assessing whether AI can support real development workflows rather than a narrow set of synthetic exercises.
Beyond function-level generation
While TabbyML notes that "developers often add code in multiple files in a single PR," private repositories enable evaluation of:
Feature implementation across microservices
Database migration and data transformation workflows
Infrastructure-as-code and deployment scenarios
API design and integration patterns
Repository-level understanding
Address the limitations of RepoBench and ExecRepoBench by providing complete project contexts where understanding requires navigating real architectural decisions and organizational constraints.
Narrow task definitions encourage narrow optimization. Diverse, repository-scale tasks reward models that understand systems rather than snippets.
Robust evaluation methodologies
Realistic tasks require equally rigorous evaluation methods. When benchmarks reflect real development scenarios, evaluation must go beyond surface-level correctness to account for integration, reliability, and long-term maintainability. Without stronger evaluation standards, even well-designed tasks can produce misleading signals about real-world readiness.
Enhanced test coverage
Move beyond HumanEval's "7.7 tests per problem" limitation by providing comprehensive test suites that reflect real-world quality standards, including integration tests, performance requirements, and security validations.
Multi-dimensional assessment
Address CRUXEval's narrow input/output prediction focus by evaluating:
Adherence to coding standards and organizational conventions
Integration with existing CI/CD pipelines
Performance and security implications
Maintainability and code quality metrics
When these factors are considered collectively, assessment moves beyond surface-level correctness and begins to reflect whether generated code can be sustained, trusted, and operated within real production environments.
Dynamic evaluation
Unlike static benchmarks that become obsolete, private repository evaluation can evolve with changing business requirements and technological landscapes.
Functional correctness alone is insufficient. Enterprises care about reliability, safety, and long-term maintainability.
Implementation framework
A realistic evaluation approach only works if it can be executed consistently, securely, and at scale. This framework describes how private repository benchmarks can be built and operated in a way that mirrors real development conditions while remaining manageable for enterprises and research teams.
Data collection strategy
Private repository benchmarks depend on data that reflects how software is actually built inside organizations. The goal is to capture authentic structure and complexity without exposing sensitive intellectual property or operational details.
Curated private repository data
The credibility of any repository-based benchmark starts with the quality and diversity of the underlying code. Data must reflect real systems as they exist in production, while still respecting confidentiality and ownership constraints.
Partner with enterprises across different industries
Extract anonymized code patterns, functions, and classes
Preserve architectural relationships while removing sensitive business logic
Include diverse technology stacks and programming languages
When curated carefully, private repositories provide the structural complexity and contextual depth that public benchmarks consistently lack, making evaluation results far more predictive of real-world performance.
Multi-modal task design
Software development spans far more than writing a single function in isolation. Benchmarks must reflect the range of work engineers perform inside evolving codebases.
Function completion: Given repository context, complete specific functions
Class implementation: Generate entire classes that integrate with existing systems
Bug reproduction: Identify and fix bugs based on issue descriptions and repository context
Refactoring challenges: Improve existing code while maintaining compatibility
This mix of tasks exposes whether models can reason across context, constraints, and change over time, rather than optimizing for narrow, one-off code generation success.
By grounding tasks in real repositories rather than synthetic prompts, this approach creates evaluations that reflect the decisions and constraints engineers face every day.
Evaluation metrics
Scoring must reflect more than whether code runs in isolation. Meaningful evaluation requires metrics that account for correctness, integration, and long-term maintainability within real systems.
Traditional metrics enhanced
Baseline performance signals still matter, but they must be evaluated in conditions that resemble real build and test environments. Enhancing familiar metrics with repository context reduces false positives that occur when code passes in isolation but fails in production.
Pass@1 with repository-specific test suites
Compilation success rates in realistic environments
Integration test completion
Other metrics
Applied this way, traditional metrics remain useful indicators of basic correctness while offering a more accurate view of whether generated code can survive real deployment workflows.
New contextual metrics
Enterprise software quality depends on factors that are invisible to functional tests alone. Contextual metrics capture whether generated code fits within an existing system rather than merely producing correct output.
Architectural compliance: Does generated code follow repository patterns?
Dependency awareness: Correctly identifies and uses existing components
Style consistency: Matches existing code conventions
Security adherence: Follows established security practices
These measures surface risks related to maintainability, security, and long-term cost, which are often where AI-generated code breaks down in real environments.
Contamination prevention
Private benchmarks only retain value if evaluation data remains cleanly separated from training data. Preventing leakage is therefore a core operational requirement, not an afterthought.
Dynamic task generation
Static benchmarks degrade quickly once models are trained on or tuned against them. Continuously refreshing evaluation tasks helps preserve the integrity of results and reduces the risk of memorization.
Automatically generate new tasks from repository patterns
Regular rotation of evaluation datasets
Version-controlled benchmark releases with clear deprecation cycles
When you treat benchmarks as living artifacts rather than fixed test sets, evaluation remains relevant as models and training data evolve.
Verification protocols
Automation alone cannot guarantee benchmark validity, especially when stakes include enterprise adoption and model comparison. Human oversight and cross-checking remain essential safeguards.
Multiple human expert reviews for each task
Cross-validation across different repository types
Ongoing monitoring for potential contamination sources
These elements form a practical foundation for evaluation that reflects real development conditions without compromising privacy or governance. This framework shifts benchmarking from theoretical capability toward operational readiness. The result is evaluation that can guide model development and enterprise adoption with far greater confidence.
Addressing potential challenges
Private repository benchmarks introduce new responsibilities around data handling, governance, and operational discipline. These challenges are manageable when safeguards are designed into the evaluation process from the outset rather than added as afterthoughts. With the right controls in place, increased realism does not have to come at the expense of trust or security.
Privacy and security concerns
Using private repositories requires strict protections to prevent exposure of sensitive code, data, or business logic. Privacy safeguards must be embedded into both dataset construction and evaluation workflows.
Implement robust anonymization techniques
Use synthetic data generation for sensitive patterns
Establish clear data governance frameworks
Regular security audits of the benchmark infrastructure
When privacy controls are treated as foundational rather than optional, organizations can participate in realistic evaluation without increasing security risk.
Governance
Clear governance defines what data can be used, how it is handled, and who is accountable at each stage of evaluation. Without explicit rules, even well-designed benchmarks can drift into legal or ethical gray areas.
Only repos with licenses permitting evaluation; track license metadata per task
Mandatory scanning and removal (e.g., credentials, tokens, emails)
Strip commit author names/emails and timestamps from task bundles
Air-gapped inference; signed evaluator attestations; audit logs
Written permission from data owners; revocation path if needed
Strong governance creates clarity and confidence for all participants, reducing friction while protecting contributors and evaluators alike.
Scalability and maintenance
For private benchmarks to remain useful, they must be sustainable over time rather than one-off research efforts. Maintenance and growth need to be planned alongside initial design.
Automated task generation from repository patterns
Community-driven contribution mechanisms
Sustainable funding models through industry partnerships
Clear benchmark lifecycle management
A scalable approach ensures benchmarks remain current as software practices, tooling, and model capabilities evolve.
Operations
Operational consistency is essential for fair comparison across models and over time. Evaluation environments must be reproducible, constrained, and transparent.
Publish Docker images with pinned deps; network-off during eval
Fixed seeds; flaky-test policy (retry ×2; mark flaky if variance >X%)
Per-task CPU/RAM/time caps; standard hardware profile
Report wall-clock and $/100 tasks for transparency
Disciplined operations prevent hidden advantages and make results interpretable for both researchers and enterprise buyers.
Industry adoption
Even the strongest benchmark has limited impact if it remains confined to research settings. Adoption depends on clear value, low friction, and alignment with existing workflows.
Start with research-friendly organizations
Demonstrate clear value through improved model evaluation
Provide tooling that integrates with existing development workflows
Establish benchmark as industry standard through consistent results
Broad adoption turns evaluation from an academic exercise into a shared reference point for progress and accountability.
These safeguards all show that realism and responsibility are not competing goals. With deliberate governance, disciplined operations, and clear incentives for adoption, private repository benchmarks can scale without compromising security or trust. This foundation is essential if more realistic evaluation is to move from isolated experimentation to broad, industry-level adoption.
The future of code generation evaluation
Enterprise adoption of LLMs for code generation is accelerating, but current evaluation methods don't match the complexity of real-world software development. By leveraging private repository data, we can create benchmarks that:
Better predict real-world performance: Models that excel on private repository benchmarks will be more likely to succeed in actual enterprise environments
Drive meaningful improvements: Developers will focus on capabilities that matter for practical software development
Enable fair comparison: Contamination-free evaluation allows for genuine model comparison
Support specialized applications: Industry-specific benchmarks can guide development of domain-focused models
Evaluation grounded in private repository data brings measurement closer to real development conditions. As a result, benchmarks can offer clearer signals about which models are ready for enterprise use and where further improvement is needed.
From benchmark theater to real-world capability
The comprehensive analysis of 18+ major code generation benchmarks reveals a troubling pattern: despite the sophistication of individual benchmarks, they collectively suffer from fundamental limitations that prevent accurate assessment of real-world coding capability. From HumanEval's artificial LeetCode-style problems to LiveCodeBench's contamination arms race, current benchmarks create what amounts to "evaluation theater"—impressive-looking assessments that fail to predict practical performance.
The evidence is compelling:
Contamination crisis: 8%-18% overlap between benchmarks and training data⁶
Performance gaps: Models achieving 91.2% on Spider 1.0 but only 21.3% on enterprise scenarios¹³
Overfitting evidence: Average 39.6% performance drops on evolved problems⁵
Context limitations: Universal failure to capture collaborative development patterns
Until evaluation reflects real development conditions, benchmark results will continue to misrepresent what AI can reliably deliver in practice.
The path forward
Private repository–based evaluation is a step change toward real-world assessment. By using enterprise code that’s access-controlled—and by not training on the test set, using a fresh, secret sample of tasks that changes regularly, and running automatic checks for look-alike questions—we can build benchmarks that greatly cut contamination risk and reflect real software work: end-to-end bug fixes, multi-file changes, and build/test (CI) and dependency constraints, all run in reproducible, containerized environments.
Show real work
Move beyond “LeetCode-style” puzzles to tasks that match how engineers actually work—multiple files, dependencies, and build/test steps.
Reduce test leakage
Don’t train on the test set, keep most test items secret and refreshed on a schedule, and run automatic checks for look-alike questions.
Reflect teamwork (when possible)
Include issue threads, code-review notes, and organizational constraints so models see context, not just a code snippet.
Fit the industry
Provide domain-specific versions (e.g., finance, healthcare, retail) with the right data shapes, rules, and latency/performance targets.
These findings point to a persistent disconnect between what benchmarks measure and what enterprises actually need from AI-assisted development. Without evaluation frameworks that reflect real repositories, real workflows, and real constraints, benchmark performance will continue to overstate readiness. Addressing this gap is a prerequisite for building AI systems that deliver reliable value beyond controlled test environments.
Beyond Better Benchmarks
The implications extend beyond evaluation methodology. As EvoEval demonstrated, models can achieve high scores on standard benchmarks while failing on evolved problems, suggesting fundamental limitations in generalization. Private repository benchmarks would drive development of LLMs that:
Understand context deeply: Navigate complex architectural relationships rather than solving isolated puzzles
Adapt to organizational patterns: Learn and apply domain-specific conventions and constraints
Support workflows: Assist with the incremental, collaborative development that characterizes enterprise software engineering
Private repository benchmarks anchor evaluation in real development environments rather than artificial test conditions. This focus encourages model progress toward deeper reliability and practical usefulness in enterprise software work.
The critical choice
The current landscape of code generation benchmarks, while academically interesting, creates a dangerous disconnect between measured capability and practical utility. As organizations increasingly depend on AI-assisted development, the quality of our evaluation frameworks will determine how effectively these tools serve real needs.
We can continue refining artificial benchmarks that models can game through memorization and pattern matching, or we can embrace the complexity of real-world software development. The choice is not just about better evaluation—it's about building AI systems that truly augment human developers rather than simply performing well on tests.
The transition to private repository-based evaluation won't be simple—it requires industry collaboration, robust privacy protections, and significant infrastructure investment. However, the alternative is continued investment in AI systems optimized for artificial benchmarks that fail when confronted with the messy, interconnected reality of enterprise software development.
As we stand at the intersection of AI advancement and software engineering evolution, the sophistication of our evaluation frameworks will determine how effectively we can harness the potential of code generation models. The time has come to move beyond benchmark theater and embrace authentic assessment of real-world capability.
How Centific helps
Centific helps organizations address these challenges by enabling evaluation and development grounded in real-world data rather than artificial benchmarks. Through our AI Data Foundry, Centific supports the creation of private, access-controlled datasets that reflect real repositories, real workflows, and real enterprise constraints, while enforcing strong separation between training and evaluation to reduce contamination risk. This approach gives businesses a practical way to test and improve AI against the conditions they will actually face in production, helping leaders move from benchmark theater toward confidence in real-world performance.
Methodology note
The benchmark coverage analysis presented in this paper represents analytical synthesis of qualitative evidence from research papers rather than empirical measurements. Scores were assigned based on documented benchmark characteristics, limitations, and performance data using a 1-5 scale across eight evaluation dimensions. While this approach provides a structured framework for comparison, future research should develop standardized quantitative metrics for these dimensions.
The scoring process involved:
Evidence Collection: Gathering qualitative descriptions from research papers and benchmark documentation
Interpretive Scoring: Translating qualitative evidence into numerical scores using logical reasoning
Pattern Identification: Analyzing universal gaps and limitations across benchmarks
This methodology has limitations including subjective interpretation, limited quantitative data, and inference requirements. The analysis should be understood as a research framework highlighting important gaps rather than definitive quantitative findings.
References
[1] Zhuo, T. Y., et al. (2024). BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions. arXiv preprint arXiv:2406.15877.
[2] Chen, M., et al. (2021). Evaluating Large Language Models Trained on Code. arXiv preprint arXiv:2107.03374.
[3] Du, X., et al. (2023). ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation. arXiv preprint arXiv:2308.01861.
[4] Gu, A., et al. (2024). CRUXEval: Code Reasoning, Understanding, and eXecution Evaluation. Facebook Research.
[5] Xia, C. S., Deng, Y., & Zhang, L. (2024). EvoEval: Evolving Coding Benchmarks via LLM. arXiv preprint arXiv:2403.19114.
[6] Yang, S., et al. (2023). Rethinking Benchmark and Contamination for Language Models with Rephrased Samples. arXiv preprint arXiv:2311.04850.
[7] Yao, F., et al. (2024). Data Contamination Can Cross Language Barriers. EMNLP 2024.
[8] Jain, N., et al. (2024). LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code. arXiv preprint arXiv:2403.07974.
[9] Ding, Y., et al. (2023). CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion. arXiv preprint arXiv:2310.11248.
[10] TabbyML Team. (2023). Cracking the Coding Evaluation. TabbyML Blog.
[11] Wang, Z., et al. (2024). ExecRepoBench: Multi-level Executable Code Completion. arXiv preprint.
[12] Zhang, S., et al. (2024). NaturalCodeBench: Examining Coding Performance Mismatch on HumanEval and Natural User Prompts. arXiv preprint arXiv:2405.04520.
[13] Lei, F., et al. (2024). Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows. arXiv preprint arXiv:2411.07763.
[14] Wang, F., et al. (2024). DevBench: A Comprehensive Benchmark for Software Development. arXiv preprint arXiv:2403.08604.
[15] Jimenez, C., et al. (2023). SWE-bench: Can Language Models Resolve Real-World GitHub Issues? arXiv preprint arXiv:2310.06770.
Appendix: Radial plot data methodology and sources
Methodology disclaimer
Important: The numerical scores (1-5) in the radial plot are analytical assessments based on qualitative evidence from research sources, not directly quoted numerical scores from the papers themselves. Most benchmark papers don't provide standardized scoring across these specific dimensions.
Source-by-source breakdown
HumanEval (Score: 1.125/5 average)
Sources Used:
Chen et al. (2021): "Evaluating Large Language Models Trained on Code"
Multiple references noting HumanEval's limitations
Evidence Informing Scores:
Real-world Alignment (1/5): "164 original pythonic programming problems, assessing language comprehension, algorithms, and simple mathematics, with some comparable to simple software interview questions" - clearly artificial academic problems
Enterprise Relevance (1/5): TabbyML analysis: "HumanEval includes mostly LeetCode's interview-style questions" - no business context
Cross-file Dependencies (1/5): "single function for LLMs to fill in the body" - explicitly single-file focus
Contamination Resistance (1/5): Multiple studies show "8-18% of the HumanEval benchmark overlaps" with training data
Collaborative Context (1/5): No evidence of team development scenarios in any source
Problem Complexity (2/5): Slightly higher due to algorithmic nature, but still basic
BigCodeBench (Scores: 2.375/5 average)
Sources Used:
Zhuo et al. (2024): "BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions"
BigCodeBench GitHub repository and leaderboard
Evidence Informing Scores:
Real-world Alignment (3/5): "1,140 programming tasks that challenge LLMs to invoke multiple function calls from 139 libraries" - more realistic than HumanEval but still artificial tasks
Enterprise Relevance (2/5): Uses real libraries but lacks business context
Cross-file Dependencies (2/5): "diverse function calls as tools" but limited cross-file scenarios
Problem Complexity (4/5): "complex instructions" and multi-library integration
Contamination Resistance (2/5): No specific contamination protection mentioned
Spider 2.0 (Score: 4.25/5 average)
Sources Used:
Lei et al. (2024): "Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows"
OpenReview paper and Spider 2.0 website
Evidence Informing Scores:
Enterprise Relevance (5/5): "632 real-world text-to-SQL workflow problems derived from enterprise-level database use cases"
Domain Specificity (5/5): "databases often containing over 1,000 columns and stored in local or cloud database systems such as BigQuery and Snowflake"
Problem Complexity (5/5): "generate multiple SQL queries with diverse operations, often exceeding 100 lines"
Real-world Alignment (5/5): "real data applications" - directly from enterprise scenarios
Contamination Resistance (4/5): Enterprise data reduces contamination risk
Cross-file Dependencies (3/5): "project-level codebases" mentioned but limited scope
Collaborative Context (3/5): Some enterprise workflow elements but not team development focus
SWE-bench (Score: 3.5/5 average)
Sources Used:
Jimenez et al. (2023): "SWE-bench: Can Language Models Resolve Real-World GitHub Issues?"
SWE-bench website and leaderboard
Evidence Informing Scores:
Real-world Alignment (4/5): "2200 GitHub issues and corresponding pull requests from 12 widely used Python repositories"
Cross-file Dependencies (4/5): Real GitHub issues require repository-wide understanding
Repository Complexity (4/5): "12 widely used Python repositories" with real complexity
Problem Complexity (4/5): Real software engineering challenges
Collaborative Context (3/5): GitHub issues involve some collaboration but limited
Enterprise Relevance (3/5): Open source focus, not enterprise-specific
Contamination Resistance (3/5): Public repositories may have contamination risk
LiveCodeBench (Score: 1.75/5 average)
Sources Used:
Jain et al. (2024): "LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code"
LiveCodeBench GitHub repository
Evidence Informing Scores:
Contamination Resistance (4/5): "continuously collects new problems over time from contests" and "problems released between May 2023 and April 2025"
Real-world Alignment (2/5): Contest problems, not development scenarios
Enterprise Relevance (1/5): Competitive programming focus
Cross-file Dependencies (1/5): Contest-style single problems
Collaborative Context (1/5): Individual competitive programming
ClassEval (Score: 1.875/5 average)
Sources Used:
Du et al. (2023): "ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation"
ClassEval GitHub repository
Evidence Informing Scores:
Problem Complexity (3/5): "class of multiple interdependent methods" - more complex than functions
Cross-file Dependencies (2/5): Within-class dependencies but not cross-file
Contamination Resistance (3/5): "manually constructed" and newer dataset
Real-world Alignment (2/5): Still artificial tasks despite class-level focus
Enterprise Relevance (2/5): "500 person-hours" to create 100 tasks - limited scope
CrossCodeEval (Score: 2.625/5 average)
Sources Used:
Ding et al. (2023): "CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion"
CrossCodeEval website
Evidence Informing Scores:
Cross-file Dependencies (4/5): "strictly require cross-file context for accurate code completion"
Real-world Alignment (3/5): "built on a diverse set of real-world, open-sourced, permissively-licensed repositories"
Repository Complexity (3/5): Real repositories but limited complexity
Enterprise Relevance (3/5): Open source focus, some business relevance
DevBench (Score: 3.63/5 average)
Sources Used:
Wang et al. (2024): "DevBench: A Comprehensive Benchmark for Software Development"
DevBench arXiv paper
Evidence Informing Scores:
Repository Complexity (5/5): "multi-file codebase starting from a product requirement document"
Problem Complexity (5/5): "software design, environment setup, implementation, and testing"
Real-world Alignment (4/5): "mirrors real-world software development"
Enterprise Relevance (4/5): Full development lifecycle
Cross-file Dependencies (4/5): Multi-file codebase focus
Collaborative Context (3/5): Some development process but limited team aspects
Dimension selection methodology
We selected the 8 dimensions based on gaps and limitations consistently mentioned across multiple sources:
Real-world Alignment: Repeatedly cited issue - TabbyML, NaturalCodeBench, multiple papers
Enterprise Relevance: Spider 2.0 motivation, enterprise deployment challenges
Cross-file Dependencies: CrossCodeEval, RepoBench, SWE-bench motivation
Repository Complexity: DevBench, SWE-bench focus areas
Contamination Resistance: Major theme across contamination studies
Domain Specificity: NaturalCodeBench, Spider 2.0 domain focus
Collaborative Context: Missing element noted in enterprise deployment discussions
Problem Complexity: Complexity escalation from HumanEval to more sophisticated benchmarks
Scoring calibration
Scoring was calibrated using these reference points:
HumanEval as baseline (mostly 1s): Well-documented limitations across all sources
Spider 2.0 as high performer: Explicitly enterprise-focused with documented real-world complexity
Limitations of this approach
What this methodology provides:
Systematic comparison across consistent dimensions
Evidence-based assessment using published research
Clear visualization of relative strengths/weaknesses
What this methodology doesn't provide:
Precise quantitative measurements from controlled studies
Head-to-head empirical comparisons on identical tasks
Validated scoring from benchmark authors themselves
Alternative approaches considered
Using only published metrics: Most papers use different metrics (Pass@1, exact match, etc.) that aren't comparable across dimensions
Creating empirical study: Would require running all benchmarks with identical evaluation framework (beyond scope)
Survey-based scoring: Would require extensive expert survey across benchmark maintainers

Categories
AI Research
Code Generation
LLM Evaluation
AI Benchmarks
Software Engineering
Share
